-
業種・地域から探す

続きの記事![]()
2025国際ロボット展
ロボット基盤モデルが拓く次世代の自動化 「生成AIの波」実世界へ
【執筆】 産業技術総合研究所 主任研究員 室岡 雅樹
生成AI(人工知能)の波が、ついにロボットの世界にも押し寄せている。大量の実世界データから動作を学習し、多様な作業を自律的にこなすロボット基盤モデルの研究が世界的に加速している。米国や中国では、ビッグテックやスタートアップが相次いで新技術を発表し、産業からサービスまで幅広い分野で自律ロボットの実現を目指す動きが活発だ。ここでは、その最新動向と今後の戦略の方向性を概観する。
世界的な盛り上がり
ロボットが経験から行動を学ぶ「ロボット学習」の研究が、いま世界的に加速している。学術分野では関連論文数が急増し、ロボット学習に特化した国際会議「Conference on Robot Learning」は、発足して10年足らずで分野を代表する会議の一つとなった。
社会実装の面でも、米国や中国を中心にビッグテックからスタートアップまで新たなロボット学習技術の発表が相次いでいる。例えば米フィギュアAIは2脚2腕のヒューマノイドロボットを物流作業に投入する「Helix」というモデルを披露し、実用現場における1時間の連続動作デモンストレーションを公開した。中国AgiBotも多数のロボット群によりデータ収集可能な施設を上海に構築し、モデル学習の基盤づくりを進めている。
潮流の起点
この潮流の始まりの一つは、2022年に米グーグルが発表したロボティクス分野における大規模な基盤モデル「(Robotics Transformer 1(RT—1)」にある。RT—1は17カ月にわたって13台のロボットで収集した約13万回の動作データを学習し、汎用的な動作生成能力を示したことで注目された。RT—1に使われた深層学習(ディープラーニング)モデル「Transformer」は、「ChatGPT」に代表される大規模言語モデルや画像生成AIの中核技術である。
言語・画像といった情報空間で成果を上げた基盤モデルの概念が、ついに実世界の物理的な動作領域にも拡張された。これが大きな転換点となった。以降、「実世界で動作する汎用モデル」すなわちロボット基盤モデルへの関心が一気に高まったのである。
ロボットが学ぶことの意義
では、ロボットが経験から学ぶとはどういうことか。これまでの産業用ロボットは高精度なハードウエアと綿密な導入設計により、「決められたことを確実に行う」点で極めて優秀だった。
しかし想定外の状況には対応できなかった。柔らかく変形する物体や透明な物体、多品種の部品を扱うような作業では、従来のティーチングやプログラミングによる教示には限界があった。
労働力不足を背景にあらゆる分野で自動化の需要が高まるなか、こうした課題を打開する手段として注目されているのが、大量の実世界データから学習したロボット基盤モデルである。これにより多様で複雑な作業をロボットが自律的にこなすことを目指す研究が、世界的に進められている。
最新技術の展開
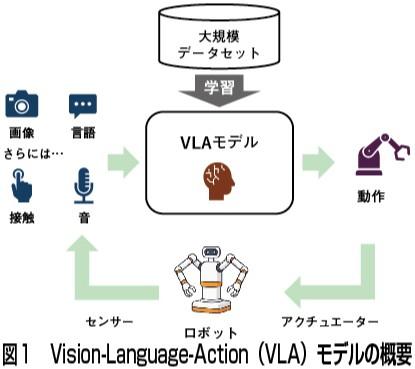
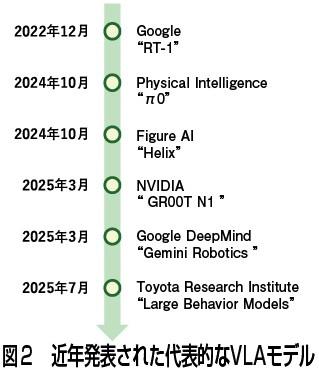
近年の研究ではこうしたロボット基盤モデルは「Vision—Language—Action(VLA)モデル」と呼ばれている(図1)。画像認識や言語理解に加え、実際の動作まで統合的に学習する点が特徴だ。この1年で多くのVLAモデルが立て続けに発表され、研究が急速に進んでいる(図2)。
例えば、米フィジカル・インテリジェンスが24年10月に公開した「π0(パイゼロ)」は、双腕モバイルマニピュレーターが洗濯物を拾い上げ、畳むという複雑な作業を自律的に実現した。生成AIの次世代手法とされる「Flow Matching」を取り入れたモデルとして注目を集めた。Flow Matchingは動作の時間的な連続性を直接学習し、より滑らかな生成を可能にする手法である。
米エヌビディアは25年3月に「GR00T N1」を発表し、シミュレーションと合成データを活用した学習基盤を提示した。さらに英グーグル・ディープマインド「Gemini Robotics」や米トヨタ・リサーチ・インスティテュートの「Large Behavior Models」なども登場。多様な動作データをまとめて学習し、異なる作業を横断的に扱えるロボットを目指す研究として成果を示している。
また、これらVLAモデルの多くはソースコードや学習済みモデルが公開されており、研究機関や企業が検証できる環境が広がっている。ただし現時点では誰もが容易に高精度な結果を再現できる段階にはなく、高度なデモには依然として環境構築やチューニングのノウハウが求められる。
今後の戦略
こうした流れを踏まえ、今後の戦略は大きく二つに分かれる。一つはVLAモデルのような基盤モデルの進化を注視し、いざというときに使いこなせる体制を整えることである。ChatGPTの登場が示したように、革新的なモデルが突如実用段階に到達する可能性はある。
計算機やデータ資源の面で開発に困難があっても、公開モデルを適切に評価し、現場に合わせて応用する力を高めておくことが重要だ。海外ではモデルをオープンにしながら開発を進める動きが広がっている。日本でもこうした国際的な潮流をうまく取り込み、信頼性や安全性を重視した応用開発へとつなげていくことが重要である。
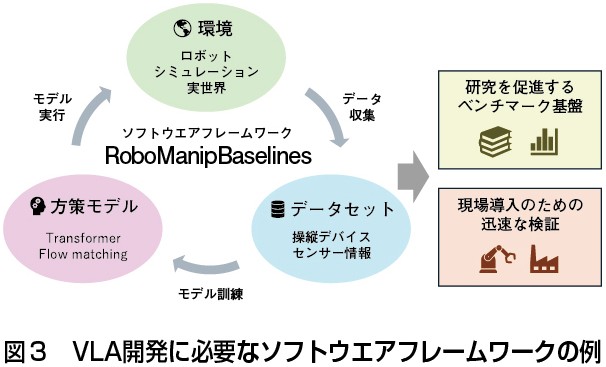
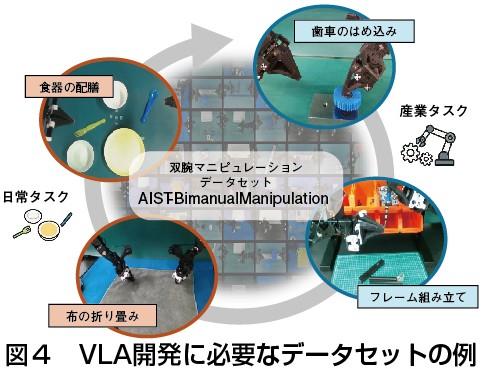
もう一つはロボット基盤モデルほど大規模な開発を目指さずとも、その基礎となる模倣学習や強化学習といった技術を実際の産業タスクに導入していく方向である。これらの手法は比較的少ないデータや計算資源でも効果を発揮できる傾向にある。実機データを少しずつ蓄積しながらモデルを改善していく「現場起点の学習」こそ、日本の産業現場に適したアプローチと言える。
産業技術総合研究所(産総研)も23年度からロボット基盤モデルに関する研究開発を開始し、25年にはソフトウエアフレームワーク「RoboManipBaselines」(図3)や双腕マニピュレーションデータセット(図4)を公開した。さらに企業と連携し、現場タスクに対する小規模模倣学習の有効性を検証しているほか、データ収集の自動化技術も開発した。現場で収集されるデータの質や量をどう高めるかが今後のカギとなる。
短期・長期で広がる研究開発
最先端の研究動向から、今後求められる研究の方向性としては、視覚や言語のみならず触覚・力覚・聴覚などの多様なセンサー情報を統合して学習する技術や、異なる身体構成のロボット間で学習モデルを共有して活用する技術、新しい環境に素早く適応できる技術の確立が挙げられる。
日本でも近年、公的な大型研究プロジェクトが相次いで立ち上がりつつある。AIロボット協会(AIRoA)によるエコシステム構築の動きは、実用化を志向した取り組みの一例である。
一方で、長期的な視点からロボット学習の基盤原理を探究する学術志向のプロジェクトも進行しており、短期と長期の双方で研究開発の動きが広がっている。今後はこうした多様な取り組みの蓄積を生かし、ロボット基盤モデルを含む多様なアプローチを通じて、日本発の信頼性と柔軟性の高いロボット技術の確立を目指していくことが期待される。

