-
業種・地域から探す

続きの記事![]()
ロボットテクノロジージャパン2026(2026年6月)
LLMを活用したロボット動作の自動生成
【執筆】中京大学 工学部 機械システム工学科 教授 橋本 学
技術者には言葉で作業内容を指示できても、同じ動作をロボットがするには位置や角度、スピード、順序など膨大な指示と専門知識が必要だった。ロボットを直接動かしながら動作を学ばせる「ダイレクトティーチング」も普及してきたが、ロボットを教示するためには製造ラインを一度止める必要があり、多品種少量生産が増加する中小企業の生産体制には適さない部分も存在した。こうしたロボットのティーチングに関する課題は、製造現場の自動化の障壁となっており、知識のない人にとっても使いやすく、変更のしやすい教示方法の開発が望まれていた。大規模言語モデル(LLM)をはじめとする生成AI(人工知能)の発展により、ロボットに言葉だけで複雑な動作を指示できるようになる可能性が見えてきた。どのようにしてロボットはモノの機能を認識し、動作をするのか。その方法を紹介する。
プログラムの作成を容易に
製造現場でロボットの活用が進む一方、現場への導入にはなお高い壁がある。ロボットに部品の持ち方や動かし方を教える「ティーチング」には専門知識と時間が必要であり、扱う部品が変わるたびに作業者が把持位置や挿入位置を細かく教え直す必要がある。
また、ロボットを動かすには専用のプログラムを作成しなければならず、プログラミングに慣れていない作業者にとっては大きな負担となる。多品種少量生産や人手不足への対応が求められる中で、ロボットに作業を教える手間を減らし、誰でも扱いやすいロボットシステムを実現することが重要な課題になっている。
製造現場でのロボット活用における課題に対し、当研究室では、ロボットへの教示やプログラム作成を簡単にする二つの技術を開発している。
一つ目は一度人が教えた部品の把持点や作用点を、形状の異なる別の部品にでも自動的に転移する技術であり、「ティーチングを簡単にする」技術である。
二つ目は大規模言語モデル(LLM)を用いて、自然言語の指示文からロボットが実行可能なプログラムを生成する技術である。すなわち「プログラムを書かなくてもロボットを動かせる」技術と位置付けられる。
ティーチングの負担を軽減
-
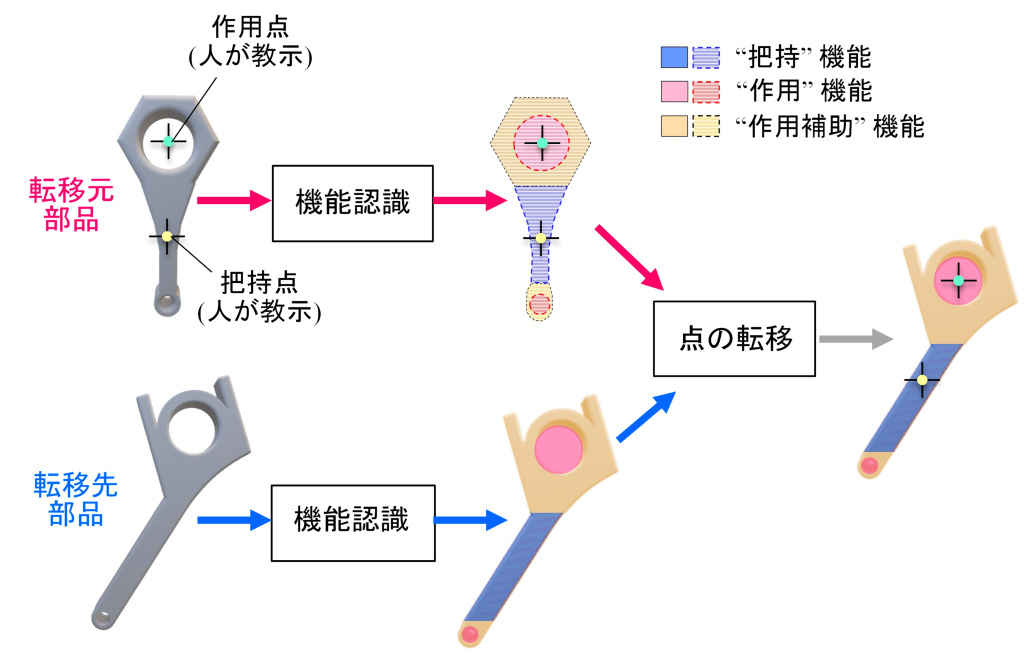
図1 部品の機能を手がかりに作業情報を転移
一つ目の技術では、工業部品は形状が異なっていても、部分的に共通した「部品機能」を持っているという考え方を用いる。
例えば、人やロボットが部品をつかむ部分、ほかの部品に差し込まれる部分、その作用を支える周辺部分などである。本手法では、部品を「把持機能領域」「作用機能領域」「作用補助機能領域」の三つに分けて認識する。把持機能領域はロボットが部品を持つ部分、作用機能領域は組み立て時にほかの部品へ差し込まれる部分、作用補助機能領域は作用機能を構成・補助する周辺部分を指す。
これらの領域を深層学習によって認識し、転移元部品と転移先部品の対応関係を求めることで、人が転移元部品に教示した把持点や作用点を、別の未知部品へ移す。
図1では、転移元部品に設定された把持点や作用点が、機能領域の対応に基づいて転移先部品へ移される様子を示している。転移元部品と転移先部品は見た目の形状が異なるが、把持する部分や作用する部分といった共通性を手がかりに対応付けを行う。
さらに、部品の輪郭を合わせる処理や簡易的な物理シミュレーションを用いることで、形状差を考慮しながら把持点と作用点を転移する。これにより、作業者は新しい部品ごとに一からロボットへ作業を教える必要がなくなり、類似部品への展開が容易になる。
評価実験では、コネクティングロッド、ボルト、コネクター、ギア、リンクを模した計40種類の工業部品を対象に、ロボット動作生成と動作パラメーター転移の性能を検証した。
人がある部品に対して教示した把持点と作用点を、形状の異なる未知部品へ転移し、実際にロボットで組み立て動作を行った。その結果、コネクティングロッドを模した部品では82・7%、ギアでは85・3%、コネクターでは75・4%、ボルトでは80・0%の動作成功率を得た。また、リンクを模した部品では、人が指定した転移結果との一致度を評価し、88・4%の成功率を示した。
実験結果から、部品の形状が変わっても、人が教示した作業情報を別部品へ再利用できる可能性が確認された。
人間の簡単な指示文で動きを実行
二つ目の技術は、自然言語の指示文からロボット動作用のプログラムをまるごと生成する技術である。近年、LLMを用いることで、人が望む処理を自然言語からプログラムとして生成することが可能になってきた。
しかし、LLMが生成したコードをそのままロボットに実行させても、必ずしも安全かつ確実に動作するとは限らない。ロボットには、対象物の位置や姿勢、周囲の障害物、センサー情報、ロボット固有の仕様など、実世界ならではの制約があるためである。
-
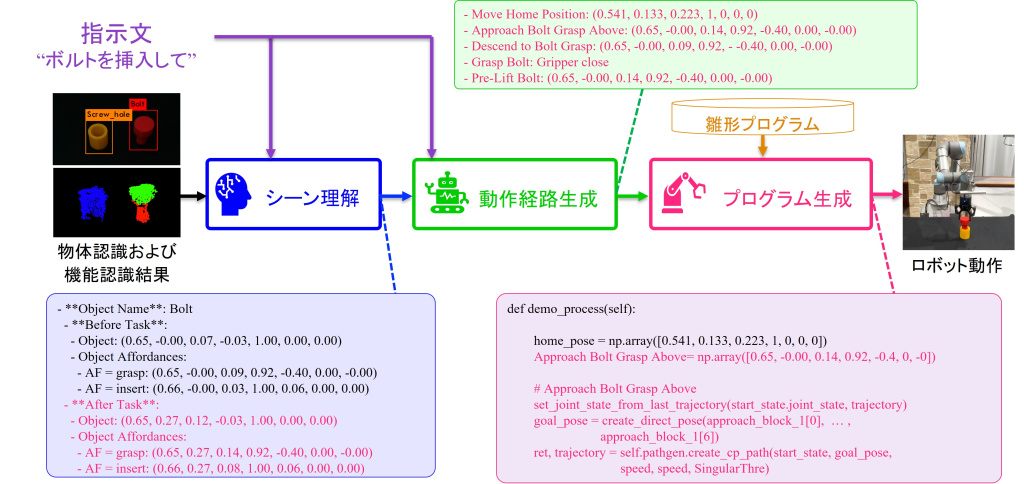
図2 自然言語指示からロボットプログラムを生成
そこで本システムでは、単にLLMにプログラムを書かせるのではなく、処理を「シーン理解」「動作経路生成」「プログラム生成」の三つの段階に分けて行う。図2では、指示文からシーン理解、動作経路生成、プログラム生成へと処理が進み、最終的にロボットが動作するまでの流れを示している。
はじめに入力として、「ブロックを箱に入れて」といったタスク指示文、物体認識済みのシーン情報、雛形プログラムを与える。シーン理解では、指示文と物体の位置・姿勢・3次元情報をもとに、タスク実行後に各物体がどこにあるべきかを推定する。
LLMの出力に誤りが含まれる可能性があるため、評価用のLLMや3次元情報を用いて結果を確認し、必要に応じて再推定を行う。
次に、動作経路生成では、タスク実行前後の物体配置に基づき、ロボットがどこを通り、どの位置で把持し、どこへ配置するかを決定する。これらの移動目標は、ロボットが扱える具体的な6自由度姿勢として出力される。
最後に、プログラム生成では、得られた動作経路と雛形プログラムをもとに、ロボットが実行可能なプログラミング言語「Python(パイソン)」コードをLLMが生成する。
-

図3 生成プログラムによるロボット動作の様子
実験では、「ブロックを箱の中に入れる」タスクと「ブロックを積み上げる」タスクを対象に、各条件で20回ずつロボットを動作させた。その結果、作業成功率は70%となり、自然言語の指示から実際にロボットが動作可能なプログラムを生成できることを確認した。
図3では、システムに「二つのブロックをそれぞれ色の異なる箱に入れて」という命令を与え、実際に生成されたプログラムにより、ロボットアームが命令を実行した様子を示している。ユーザーは詳細な制御コードを一から書く必要がなく、作業内容を簡単なテキストで与えるだけで、システムが動作手順と実行コードを生成する。
現場で導入しやすい技術へ
-

図4 「機能認識技術」を活用し道具の使い方を認識する「お茶会ロボット」を開発した
近年は、視覚、言語、行動を統合してロボットを制御する「フィジカルAI」への関心が高まっている。特に、視覚・言語・行動を一体的に扱うVLA(視覚言語行動モデル)は、今後のロボット制御基盤として期待されている。
一方で、すべてを一つの大規模モデルに任せるのではなく、視覚認識、3次元情報処理、動作計画を役割分担させてモジュール化する方法も有効である。今回の研究は、その一例といえる。LLMが指示文の意味理解や手順生成を担い、視覚モジュールで物体の位置や姿勢を認識し、動作経路生成モジュールでロボットの具体的な動きへ落とし込む。このように機能を分けることで、誤りの検出や修正がしやすくなり、実環境で使いやすいシステムを構築できる可能性がある。
今回紹介した二つの技術は、いずれもロボットを専門家だけのものにせず、より多くの現場で扱いやすくすることを目指している。部品機能に基づく動作パラメーター転移は、ティーチングの負担を軽減し、自然言語指示に基づくプログラム生成は、専門性の高いプログラミングの負担を減らす。
人が簡単に指示し、ロボットが環境を理解して柔軟に動作する製造支援システムの実現が期待される。
当研究室では、ロボットティーチングの効率化や組み立て作業の自動化、自然言語によるロボット制御などに関心を持つ企業・研究機関との共同研究も歓迎している。現場の課題に合わせた応用展開を進め、実用化に向けた検証を重ねていく(図4)。